Getting started with timeseries¶
This notebook will walk you through some of the basic methods in PTSA’s TimeSeries class. We’ll see how to construct an instance of TimeSeries, how to save and load data, as well as resampling and filtering TimeSeries.
[1]:
# relevant imports
import numpy as np
from matplotlib import pyplot as plt
%matplotlib inline
from ptsa.data.timeseries import TimeSeries
Let’s start with creating some data¶
[2]:
num_points = 5000
sample_rate = 10.
# We can specify the timestamps for each data point, from 0s to 500s.
t = np.linspace(1, num_points, num_points) / sample_rate
# Let's create two noisy sinusoids with different frequencies.
frequency1 = .5 # 1 cycle every 2 seconds
frequency2 = .1 # 1 cycle every 10 seconds
data1 = np.sin(2*np.pi*frequency1*t) + np.random.uniform(-0.5, 0.5, num_points)
data2 = np.sin(2*np.pi*frequency2*t) + np.random.uniform(-0.5, 0.5, num_points)
Let’s check our timepoints.
[3]:
print ('First 5 timestamps: ', t[:5])
print ('Last 5 timestamps: ', t[-5:])
First 5 timestamps: [0.1 0.2 0.3 0.4 0.5]
Last 5 timestamps: [499.6 499.7 499.8 499.9 500. ]
We can also visualize the timeseries using matplotlib.
[4]:
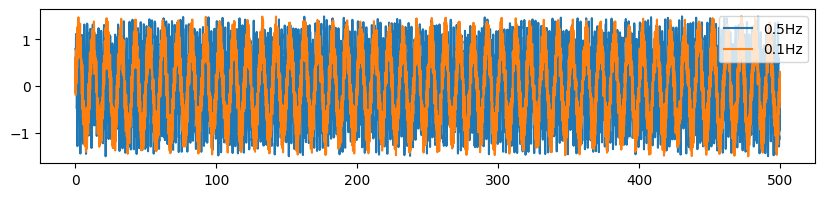
plt.figure(figsize=[10,2])
plt.plot(t, data1, label='%sHz'%str(frequency1))
plt.plot(t, data2, label='%sHz'%str(frequency2))
plt.legend()
[4]:
<matplotlib.legend.Legend at 0x7f627323afd0>
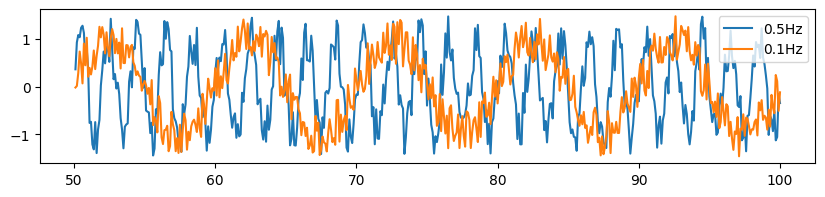
As we zoom in to the data array, the random noise we added to the sinusoids becomes clear.
[5]:
plt.figure(figsize=[10, 2])
plt.plot(t[500:1000], data1[500:1000], label='%sHz'%str(frequency1))
plt.plot(t[500:1000], data2[500:1000], label='%sHz'%str(frequency2))
plt.legend()
[5]:
<matplotlib.legend.Legend at 0x7f6272c90b10>
Create a TimeSeries object¶
The TimeSeries class is a convenient wrapper of xarray that offers basic functionalities for timeseries analysis. Although we focus our analysis here in the context of timeseries data, many of the following examples can be easily extended to non-timeseries, multidimensional data. To create a TimeSeries object, we simply need to construct dimensions and the corresponding coordinates in each dimension.
[6]:
# Let's stack the two time-series data arrays.
data = np.vstack((data1, data2))
# and construct the TimeSeries object
ts = TimeSeries(data,
dims=('frequency', 'time'),
coords={'frequency':[frequency1, frequency2],
'time':t,
'samplerate':sample_rate})
print (ts)
<xarray.TimeSeries (frequency: 2, time: 5000)> Size: 80kB
array([[ 0.59138778, 0.40932715, 0.80904355, ..., -0.48213069,
-0.43585259, -0.36367577],
[-0.17560236, 0.58995205, -0.14297665, ..., -0.33518201,
0.30790414, -0.0773072 ]], shape=(2, 5000))
Coordinates:
* frequency (frequency) float64 16B 0.5 0.1
* time (time) float64 40kB 0.1 0.2 0.3 0.4 ... 499.7 499.8 499.9 500.0
samplerate float64 8B 10.0
TimeSeries also has a convenient plotting method, inherited from xarray.
Note: since the frequency dimension has float coordinates, we want to be careful for exact float comparisons. Thus, instead of using ts.sel(frequency=frequency1), we use ts.sel(frequency=ts.frequency[0]). See more about the .sel() method in later sections.
[7]:
plt.figure(figsize=[10,2])
ts.sel(frequency=ts.frequency[0]).plot()
[7]:
[<matplotlib.lines.Line2D at 0x7f6272d62b90>]
Saving and loading your data¶
TimeSeries objects can be easily saved and loaded in HDF5 format.
Note: You will need to install h5py to use these methods.
[8]:
ts
[8]:
<xarray.TimeSeries (frequency: 2, time: 5000)> Size: 80kB
array([[ 0.59138778, 0.40932715, 0.80904355, ..., -0.48213069,
-0.43585259, -0.36367577],
[-0.17560236, 0.58995205, -0.14297665, ..., -0.33518201,
0.30790414, -0.0773072 ]], shape=(2, 5000))
Coordinates:
* frequency (frequency) float64 16B 0.5 0.1
* time (time) float64 40kB 0.1 0.2 0.3 0.4 ... 499.7 499.8 499.9 500.0
samplerate float64 8B 10.0[9]:
# use to_hdf to save data
fname = 'my_ts_data.h5'
ts.to_hdf(fname)
[10]:
# use from_hdf to load data
ts = TimeSeries.from_hdf(fname)
print (ts)
<xarray.TimeSeries 'data' (frequency: 2, time: 5000)> Size: 80kB
array([[ 0.59138778, 0.40932715, 0.80904355, ..., -0.48213069,
-0.43585259, -0.36367577],
[-0.17560236, 0.58995205, -0.14297665, ..., -0.33518201,
0.30790414, -0.0773072 ]], shape=(2, 5000))
Coordinates:
* frequency (frequency) float64 16B 0.5 0.1
* time (time) float64 40kB 0.1 0.2 0.3 0.4 ... 499.7 499.8 499.9 500.0
samplerate float64 8B 10.0
Indexing your data¶
We can used xarray’s .sel() method to index our data, or give the dimension name instead of the dimension index to other methods.
Click here to learn more about xarray methods.
[11]:
# Select the data from 100s to 200s
ts.sel(time=(ts.time>100)&(ts.time<200))
[11]:
<xarray.TimeSeries 'data' (frequency: 2, time: 999)> Size: 16kB
array([[ 0.69955587, 0.17406547, 1.15196174, ..., -0.85261276,
-0.42994665, 0.01449475],
[ 0.09292001, -0.28947634, 0.10547123, ..., 0.06356814,
0.05708609, 0.24974045]], shape=(2, 999))
Coordinates:
* frequency (frequency) float64 16B 0.5 0.1
* time (time) float64 8kB 100.1 100.2 100.3 100.4 ... 199.7 199.8 199.9
samplerate float64 8B 10.0[12]:
# mean over the time dimension
ts.mean('time')
[12]:
<xarray.TimeSeries 'data' (frequency: 2)> Size: 16B
array([-0.00353038, -0.00325323])
Coordinates:
* frequency (frequency) float64 16B 0.5 0.1
samplerate float64 8B 10.0Matching coordinates¶
We can also place the time dimension as the first dimension. The coordinates in xarray are very useful and are used to keep track of the dimensions of the data. Therefore, the exact shape of the data or the order of the dimensions can vary.
[13]:
ts_transpose = ts.T
print (ts_transpose)
<xarray.TimeSeries 'data' (time: 5000, frequency: 2)> Size: 80kB
array([[ 0.59138778, -0.17560236],
[ 0.40932715, 0.58995205],
[ 0.80904355, -0.14297665],
...,
[-0.48213069, -0.33518201],
[-0.43585259, 0.30790414],
[-0.36367577, -0.0773072 ]], shape=(5000, 2))
Coordinates:
* frequency (frequency) float64 16B 0.5 0.1
* time (time) float64 40kB 0.1 0.2 0.3 0.4 ... 499.7 499.8 499.9 500.0
samplerate float64 8B 10.0
We can try adding the original timeseries and its “transposed” version together. Because their coordinates match, operations can be performed between them even though the data arrays are technically of different shapes. Note that because the transposed version of the data has the same value at every coordinate, by adding them together we’re effectively doubling the values.
[14]:
results = ts + ts_transpose
plt.figure(figsize=[10, 3])
# we'll only plot the first 250 samples to see things clearly
plt.plot(ts.time[:250], ts.sel(frequency=ts.frequency[0])[:250], label='original')
plt.plot(results.time[:250], results.sel(frequency=ts.frequency[0])[:250], label='original+transposed')
plt.ylim([-4,4])
plt.legend(ncol=2)
[14]:
<matplotlib.legend.Legend at 0x7f6268762990>
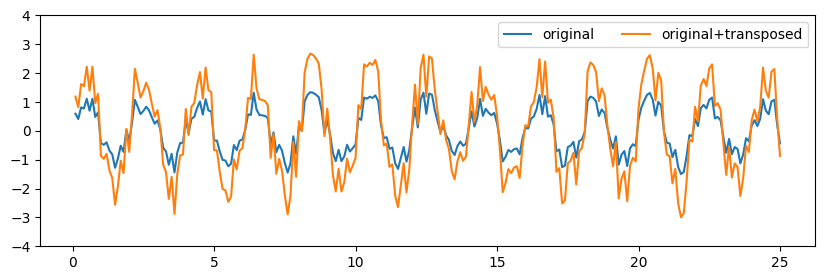
Without the coordinates, the data cannot be added because their shapes wouldn’t match.
[15]:
try:
print (data+data.T)
except Exception as e:
print ('Error: ' + str(e))
Error: operands could not be broadcast together with shapes (2,5000) (5000,2)
Note that sometimes, this feature can produce undesired results. Suppose that we want to subtract a subset of our data from another subset of our data, because xarray matches coordinates, it will drop all unmatched coordinates and return 0 at each matched coordinate.
[16]:
# Recall that our data contains 5000 points.
# Let's select the first 3000 points and the last 3000 points and subtract one from the other.
# The result is all zeros because unmatched coordinates are dropped,
# and the value at each of the 1000 overlapping coordinates is subtracted from itself.
early_ts = ts.sel(time=ts.time[:3000])
late_ts = ts.sel(time=ts.time[2000:])
print (late_ts - early_ts)
<xarray.TimeSeries 'data' (frequency: 2, time: 1000)> Size: 16kB
array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]], shape=(2, 1000))
Coordinates:
* frequency (frequency) float64 16B 0.5 0.1
* time (time) float64 8kB 200.1 200.2 200.3 200.4 ... 299.8 299.9 300.0
samplerate float64 8B 10.0
[17]:
# However, if we only subtract the underlying data arrays,
# it will return the actual difference of the early subset and the late subset of our timeseries.
print (late_ts.values - early_ts.values)
[[ 0.20983155 0.36970144 -0.297799 ... 0.4467902 -0.50094022
-0.31189185]
[-0.02704539 -0.37381149 0.03576926 ... -0.51795516 0.4756635
0.1212194 ]]
Resampling your data¶
We can resample the data to a specific samplerate.
[18]:
original = ts.sel(frequency=ts.frequency[0]).sel(time=ts.time<50.0)
downsampled = original.resampled(resampled_rate=2.0)
[19]:
plt.figure(figsize=[10, 4])
plt.plot(original.time, original, color='C0', label='10.0Hz samplerate (original)')
plt.plot(downsampled.time, downsampled, color='C6', label='2.0Hz samplerate (downsampled)')
plt.legend()
[19]:
<matplotlib.legend.Legend at 0x7f6260bf9e50>
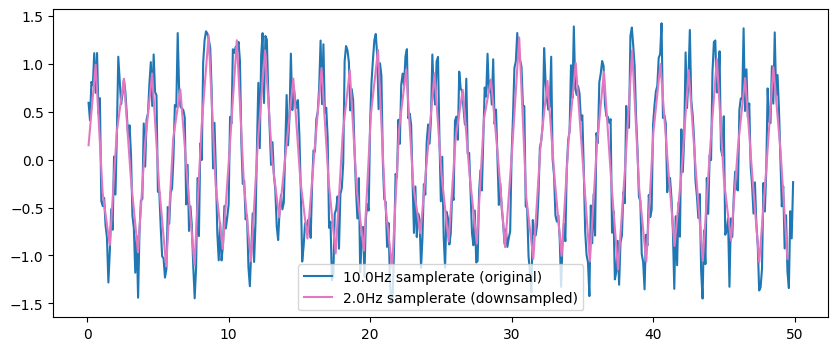
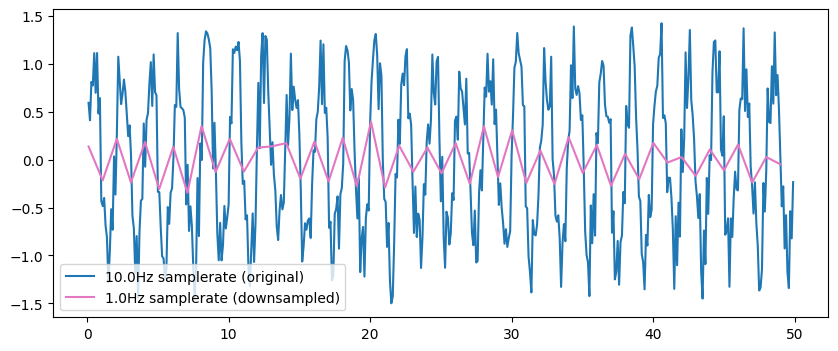
However, as we downsample to lower frequencies, we lose precision of the signal.
Read more about the relationship between sampling rate and observed frequencies here.
[20]:
original = ts.sel(frequency=ts.frequency[0]).sel(time=ts.time<50.0)
downsampled = original.resampled(resampled_rate=1.0)
plt.figure(figsize=[10, 4])
plt.plot(original.time, original, color='C0', label='10.0Hz samplerate (original)')
plt.plot(downsampled.time, downsampled, color='C6', label='1.0Hz samplerate (downsampled)')
plt.legend()
[20]:
<matplotlib.legend.Legend at 0x7f6260c79f90>
[21]:
# TimeSeries updates the samplerate for you
print (original.samplerate)
print (downsampled.samplerate)
<xarray.TimeSeries 'samplerate' ()> Size: 8B
array(10.)
Coordinates:
frequency float64 8B 0.5
samplerate float64 8B 10.0
<xarray.TimeSeries 'samplerate' ()> Size: 8B
array(1.)
Coordinates:
samplerate float64 8B 1.0
Filtering your data¶
Let’s create a new TimeSeries object composed of sinunoids at three different frequencies. We’ll show how to manipulate these data using different filtering methods.
[22]:
freq1 = 3.2
freq2 = 1.6
freq3 = 0.2
data1 = np.sin(2*np.pi*freq1*t)
data2 = np.sin(2*np.pi*freq2*t)
data3 = np.sin(2*np.pi*freq3*t)
# our data are simply the sum of the three sinusoids
data = data1 + data2 + data3
[23]:
ts = TimeSeries(data, dims=('time'), coords={'time':t, 'samplerate':sample_rate})
print (ts)
<xarray.TimeSeries (time: 5000)> Size: 40kB
array([ 1.87448821e+00, 3.83003697e-01, 2.44767899e-01, ...,
-3.83003697e-01, -1.87448821e+00, 9.82193362e-14], shape=(5000,))
Coordinates:
* time (time) float64 40kB 0.1 0.2 0.3 0.4 ... 499.7 499.8 499.9 500.0
samplerate float64 8B 10.0
[24]:
# Let's plot the first 200 samples of the data
fig, ax = plt.subplots(4, figsize=[10, 4], sharex=True, sharey=True)
ax[0].plot(t[:200], data1[:200])
ax[1].plot(t[:200], data2[:200])
ax[2].plot(t[:200], data3[:200])
ax[3].plot(t[:200], ts[:200])
ax[0].set_ylabel('3.2Hz')
ax[1].set_ylabel('1.6Hz')
ax[2].set_ylabel('0.2Hz')
ax[3].set_ylabel('sum')
ax[3].set_xlabel('Time(s)')
[24]:
Text(0.5, 0, 'Time(s)')
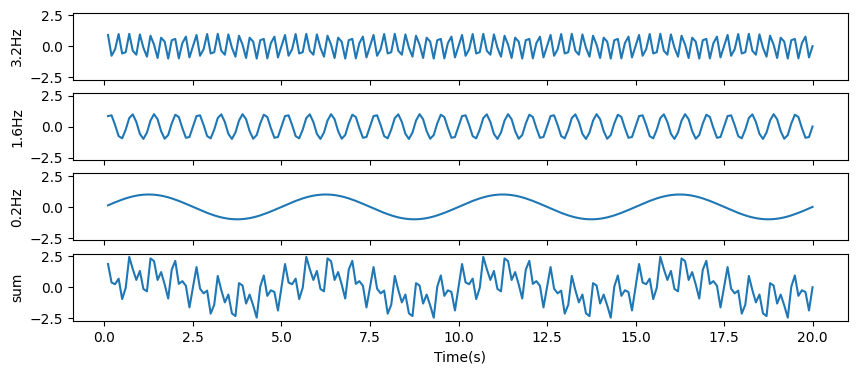
We will use three different filters to filter out each component.¶
To filter out the component with the highest frequency (3.2Hz), we’ll use a lowpass filter. A lowpass filter perserves any frequency that is lower than the given frequency.
To filter out the component with the lowest frequency (0.2Hz), we’ll use a highpass filter. A highpass filter perserves any frequency that is higher than the given frequency.
To filter out the component with the middle frequency (1.6Hz), we’ll use a bandstop filter. A bandstop filter perserves any frequency that is outside of the given frequency range.
Note that these filters suffer from edge effects at both ends of the timeseries.
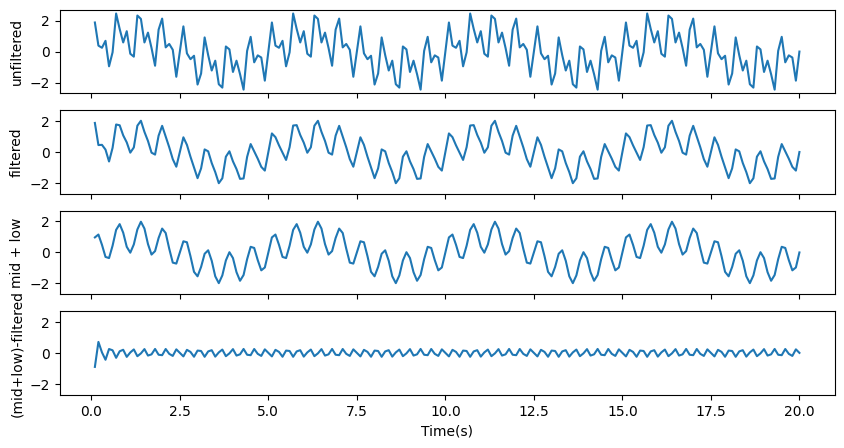
[25]:
# lowpass filter
filtered_data = ts.filtered(3.0, filt_type='lowpass', order=4)
fig, ax = plt.subplots(4, figsize=[10, 5], sharex=True, sharey=True)
ax[0].plot(t[:200], ts[:200]) # origianl timeseries
ax[1].plot(t[:200], filtered_data[:200]) # losspass filtered
ax[2].plot(t[:200], (data2+data3)[:200]) # what we should get (mid + low frequencies)
ax[3].plot(t[:200], (data2+data3-filtered_data)[:200]) # the difference between what we should get and what we got should be close to zero
ax[0].set_ylabel('unfiltered')
ax[1].set_ylabel('filtered')
ax[2].set_ylabel('mid + low')
ax[3].set_ylabel('(mid+low)-filtered')
ax[3].set_xlabel('Time(s)')
/home1/rdehaan/dependencies/ptsa/.claude/worktrees/agent-a217f6b682d8dd9b8/ptsa/data/timeseries.py:428: UserWarning: The filtered method is not very flexible and will be deprecated in an upcoming release.Consider using filters in ptsa.data.filters instead.
warnings.warn(
[25]:
Text(0.5, 0, 'Time(s)')
[26]:
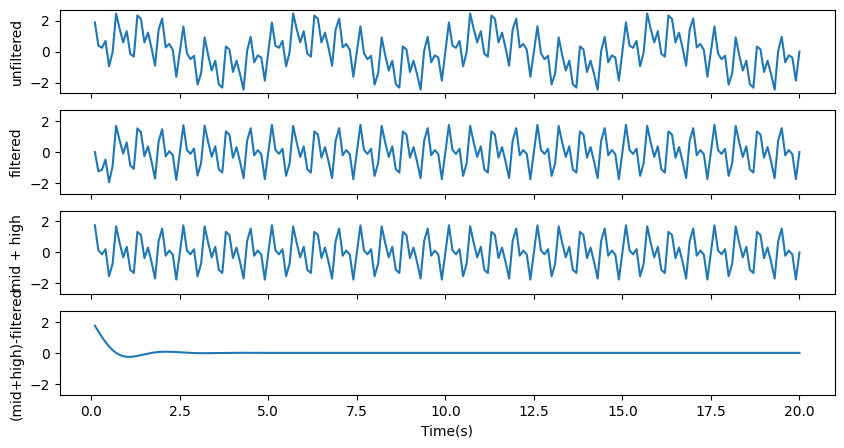
# highpass filter
filtered_data = ts.filtered(0.5, filt_type='highpass', order=4)
fig, ax = plt.subplots(4, figsize=[10, 5], sharex=True, sharey=True)
ax[0].plot(t[:200], ts[:200]) # origianl timeserids
ax[1].plot(t[:200], filtered_data[:200]) # highpass filtered
ax[2].plot(t[:200], (data2+data1)[:200]) # what we should get (mid + high frequencies)
ax[3].plot(t[:200], (data2+data1-filtered_data)[:200]) # the difference between what we should get and what we got should be close to zero
ax[0].set_ylabel('unfiltered')
ax[1].set_ylabel('filtered')
ax[2].set_ylabel('mid + high')
ax[3].set_ylabel('(mid+high)-filtered')
ax[3].set_xlabel('Time(s)')
[26]:
Text(0.5, 0, 'Time(s)')
[27]:
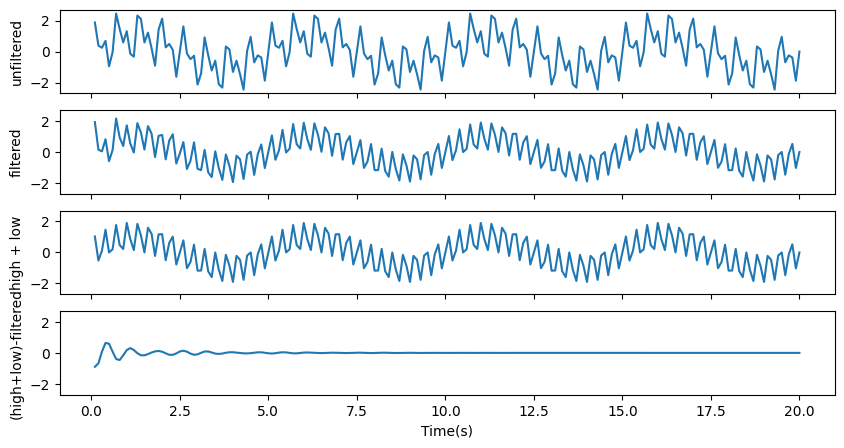
# bandstop filter
filtered_data = ts.filtered([1.4, 1.8], filt_type='stop', order=4)
fig, ax = plt.subplots(4, figsize=[10, 5], sharex=True, sharey=True)
ax[0].plot(t[:200], ts[:200]) # origianl timeserids
ax[1].plot(t[:200], filtered_data[:200]) # bandstop filtered
ax[2].plot(t[:200], (data1+data3)[:200]) # what we should get (high + low frequencies)
ax[3].plot(t[:200], (data1+data3-filtered_data)[:200]) # the difference between what we should get and what we got should be close to zero
ax[0].set_ylabel('unfiltered')
ax[1].set_ylabel('filtered')
ax[2].set_ylabel('high + low')
ax[3].set_ylabel('(high+low)-filtered')
ax[3].set_xlabel('Time(s)')
[27]:
Text(0.5, 0, 'Time(s)')